






繼火爆出圈的Grounded SAM之後,IDEA研究院團隊攜重磅新作歸來:全新視覺提示(Visual Prompt)模型T-Rex,以圖識圖,開箱即用,開啟開集檢測新天地!

(動態圖)
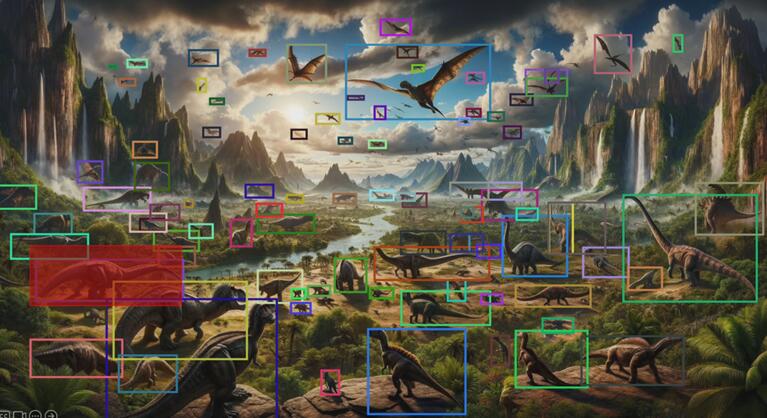
(靜態圖)
拉框、檢測、完成!在剛剛結束的2023 IDEA大會上,IDEA研究院創院理事長、美國國家工程院外籍院士沈向洋展示了基於視覺提示的目標檢測新體驗,並發布了全新視覺提示模型T-Rex的模型實驗室(playground), Interactive Visual Prompt(iVP),掀起現場一波試玩小高潮。
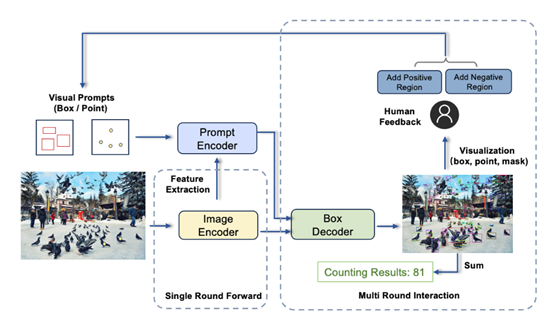
在iVP上,用戶可以親自解鎖「一圖勝千言」的prompting體驗:在圖片上標記感興趣的對象,向模型提供視覺示例,模型隨即檢測出目標圖片中與之相似的所有實例。整套流程交互便捷,只需幾步操作就可輕鬆完成。
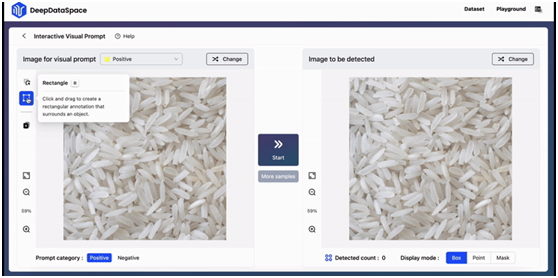
(動態圖)
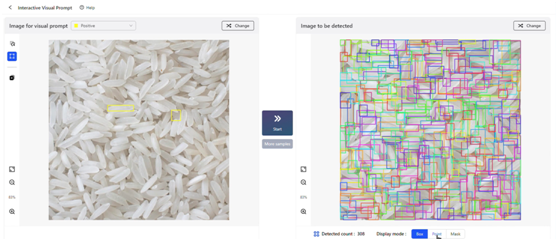
(靜態圖)
IDEA研究院4月份發布的Grounded SAM (Grounding DINO + SAM) 曾在Github上火爆出圈,至今已狂攬11K星。有別於只支持文字提示的Grounded SAM,此次發布的T-Rex模型提供着重打造強交互的視覺提示功能。
T-Rex具備極強的開箱即用特性,無需重新訓練或微調,即可檢測模型在訓練階段從未見過的物體。該模型不僅可應用於包括計數在內的所有檢測類任務,還為智能交互標註場景提供新的解決方案。

團隊透露,研發視覺提示技術是源自對真實場景中痛點的觀察。有合作方希望利用視覺模型對卡車上的貨物數量進行統計,然而,僅通過文字提示,模型無法單獨識別出每一個貨物。其原因是工業場景中的物體在日常生活中較為罕見,難以用語言描述。在此情況下,視覺提示顯然是更高效的方法。與此同時,直觀的視覺反饋與強交互性,也有助於提升檢測的效率與精準度。
基於對實際使用需求的洞察,團隊將T-Rex設計成可接受多個視覺提示的模型,且具備跨圖提示能力。除了最基本的單輪提示模式,目前模型還支持以下三種進階模式。

• 多輪正例模式:適用於視覺提示不夠精準造成漏檢的場景
• 正例+負例模式: 適用於視覺提示帶有二義性造成誤檢的場景
• 跨圖模式:適用於通過單張參考圖提示檢測他圖的場景
在同期發布的技術報告中,團隊總結了T-Rex模型的四大特性:
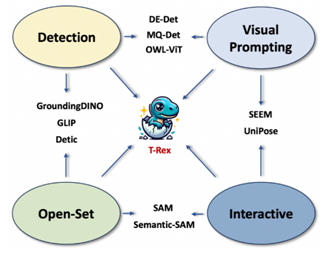
開放集:不受預定義類別限制,具有檢測一切物體的能力
視覺提示:利用視覺示例指定檢測目標,克服罕見、複雜物體難以用文字充分表達的問題,提高提示效率
直觀的視覺反饋:提供邊界框等直觀視覺反饋,幫助用戶高效評估檢測結果
交互性:用戶便捷參與檢測過程,對模型結果進行糾錯
研究團隊指出,在目標檢測場景中,視覺提示的加入能夠補足文本提示的部分缺陷。未來,兩者的結合將進一步釋放CV技術在更多垂直領域的落地潛能。
有關T-Rex模型的技術細節,請參考同期發布的技術報告。
iVP 模型實驗室:https://deepdataspace.com/playground/ivp
Github連結:trex-counting.github.io
本項工作來自IDEA研究院計算機視覺與機械人研究中心。該團隊此前開源的目標檢測模型DINO是首個在COCO目標檢測上取得榜單第一的DETR類模型;在Github上大火的零樣本檢測器Grounding DINO與能夠檢測、分割一切的Grounded SAM,同樣為該團隊作品。





電話:(香港)852-2564 0768
(深圳)86-755-83518792 83517835 83518291
地址:香港九龍觀塘道332號香港商報大廈









