
被譽為英國半導體之父,也是Arm聯合創始人的Hermann Hauser曾經這樣說:“在計算機歷史上只發生過三次革命,第一次是70年代的CPU,第二次是90年代的GPU,而Graphcore就是第三次革命。” 他所指的正是Graphcore率先提出的就是為AI計算而生的IPU(Intelligence Processing Unit)。

內存牆是阻礙AI芯片性能提升的關鍵,因此計算架構的創新變得更加重要,不過這其中大部分的架構創新都是在已有的架構基礎上。Graphcore聯合創始人兼CEO Nigel Toon在ASPENCORE主辦的2019 CEO峰會期間接受雷鋒網采訪時表示,Graphcore開創了全新的處理器類型IPU,IPU是專為機器智能設計的處理器,能夠滿足人們對高效易于使用的處理器的需求。

左:Graphcore銷售副總裁/中國區總經理盧濤,右:Graphcore聯合創始人兼CEO Nigel Toon
左右逢源的英國AI獨角獸
Graphcore在風險資本的支持下于2016年在英國成立,成立三年時間,就獲得了3.25億美元的融資,去年估值就達到了17億美元,其中的投資者既有像紅杉資本這樣的金融投資者,也有像戴爾、三星、微軟等的戰略投資者。
除了資本的認可,Graphcore還獲得了多位AI領域的知名學術投資人為其背書,比如DeepMind 的聯合創始人 Demis Hassabis、劍橋大學的 Zoubin Ghahramani 和 Uber 的首席科學家、加州大學伯克利的 Pieter Abbeel 以及 OpenAI 的 Greg Brockman、Scott Grey 和 Ilya Sutskever等。
被稱為AI教父Geoff Hinton就曾說,“我認為我們需要轉向不同類型的計算機。幸運的是,我這里有一個。”Hinton伸手進入他的錢包,拿出一個又大又亮的硅片,這個硅片就是Graphcore的IPU。

創立這家獲得學界和資本都認可的兩位創始人是Nigel Toon和Simon Knowles,Graohcore也是他們的第二次創業。 2002年,Toon和Knowles(現任Graphcore CTO)在英國Bristol共同創辦了Icera,致力于打造3G modem芯片,2011年被英偉達以3.7億美元的價格收購。
在Icera被收購之後不久,Nigel Toon和Simon Knowles就在思考再次進行創業,基于兩位創始人的經驗以及對未來的判斷,在2016年創立了了Graphcore。如今,Graphcore在倫敦、劍橋、台灣、北京、Palo Alto、Oslo都設有辦公室,員工人數將在今年底達到400人,IPU也已經于去年底推出。
那麼,IPU為何能受到如此多的關注和期待?
全新類型處理器架構——IPU
Nigel認為,AI有三類芯片,第一類是簡單的小型化加速器,用于手機、傳感器等;第二類是ASIC,比如谷歌的TPU;第三類是可編程處理器,目前市場上只有GPU,Graphcore的IPU屬于這個分類,但又有所不同,因為IPU是一個非常靈活的處理器,從零開始,是專門針對AI設計的處理器架構,在未來很多新的AI應用中,IPU也會表現的更好。
之所以要推出IPU,是因為Nigel看到,如果只是針對基本的前饋卷積神經網絡,GPU是一個非常好的解決方案,但隨着網絡變得越來越復雜,人們需要一個新的解決方案,ASIC和FPGA的采用就已經證明了GPU的弱點。
“我們接觸過的所有創新者都說使用GPU正在阻礙他們創新。如果仔細看一下他們正在研究的模型類型,你會發現他們主要研究卷積神經網絡,遞歸神經網絡和其他類型的結構,例如強化學習,並不能很好地映射到GPU。這也正是我們將IPU推向市場的主要原因。”
Nigel指出,IPU是我們開創的一個全新的處理器類型,專為AI設計,IPU強大的並行處理能力實現了快速訓練模型並進行實時操控。其實現在有一些國外公司也在說他們的產品叫IPU,但我們首創的這個叫法,而且技術產品跟我們相比還差很多。
那IPU架構到底獨特在哪里?Graphcore銷售副總裁/中國區總經理盧濤對雷鋒網表示,Graphcore的IPU里面有1216個核,我們稱之為Tile,每個Tile里都有計算單元和內存。由于同時有上千個處理器工作,所以單個IPU的存儲带寬能達到45TB,比性能最快的HBM提升了50倍以上,在相同算力下,功耗也降低了一半。
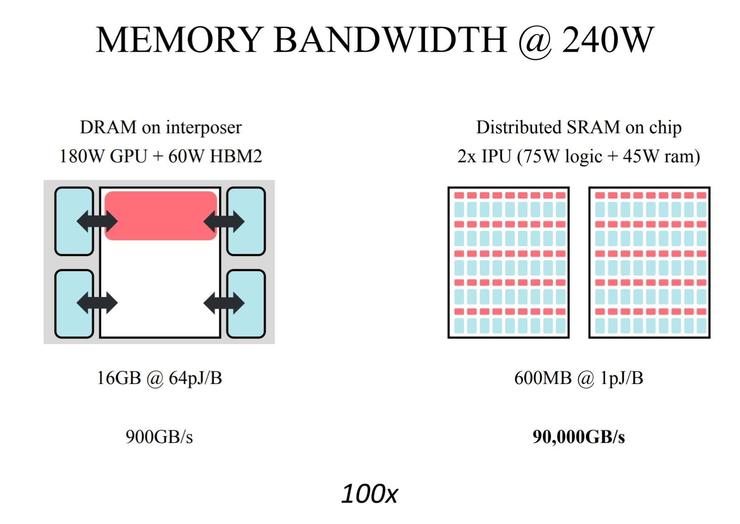
根據Graphcore的說法,IPU處理器是迄今為止最復雜的處理器芯片,基于16納米的工藝集成了240億個晶體管,每個芯片提供125 teraFLOPS運算能力。借助IPU,一個完整的機器學習模型可以在處理器內部處理。而且IPU處理器具有數百兆字節的RAM,可在處理器上以1.6 GHz的速率全速運行。
但是,提高带寬的同時,如何解決數據的通信以及提升數據的使用效率就是非常關鍵的問題,也是關鍵挑戰。盧濤表示, IPU內部里有一個叫all-to-all總線,這個互聯總線,可以高速實現任意一個核到另外一個核的直接訪問。涉及到跨多個芯片的時,通過IPU-Link就可以把多個IPU聯結在一起,組成一個集群。當然,all-to-all總線中間的BSP(Bulk Synchronous Parallel)協議,不僅用于同一個芯片的不同核之間,而且跨芯片的核之間也可以通過該協議透過 IPU-Link 總線進行通信。
IPU-Link最多可以支持128個芯片的互聯,如果要進行更大規模的訓練,可以通過以太網或者Infiniband進行互聯,另外針對超大規模AI 訓練應用,Graphcore還開發了專門的IPU-POD。IPU-POD 是由 IPU-machine 組成的 POD,每個 IPU-machine 上集成的IPU-Gateway芯片里有一個叫做IPUoF的技術,能夠把幾千甚至幾萬顆的 IPU 處理器連在一起。
解決了數據通信的問題,還有數據的效率問題。IPU沒有采用傳統處理器架構中保證多個處理器數據一致性的Cache協議,而是通過BSP配合Poplar軟件棧的方式來提升效率。Nigel Toon表示,很多人都部署了BSP,但只是用在主機之間,也就是大規模的並行機制,我們在芯片上實現了BSP,同時配合Poplar的軟件棧工具/編譯器,它會把算法模型、數據處理之後,映射或者分配到處理器的不同位置,並定義好交換和同步的時間等,不僅更易于使用,而且具有足夠的靈活性。
這樣即使對于算法公司而言,雖然處理器有1000多個核,7000多個線程,但是不需要太擔心通信的問題,能夠讓算法工程师非常方便地用。
Nigel Toon總結表示,IPU與其它的AI芯片相比,有三個比較核心的區別:
第一,處理器核的架構不同,IPU是MIMD的架構。
第二,IPU的模型在處理器內。
第三,大規模並行,IPU核之間的通信效率也非常高,這非常難,Graphcore進行了大量的創新。

相同的IPU硬件就可用于推理和訓練
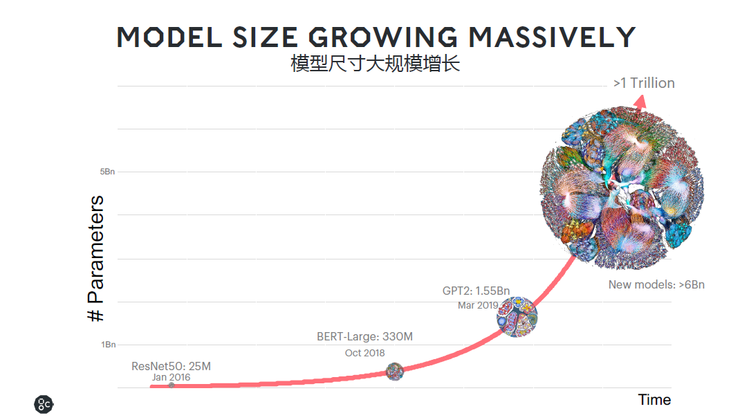
對于芯片公司而言,設計出獨特的芯片並不是最難的,更難的是獲得客戶的認可和采用。Nigel Toon表示,未來幾年Graphcore都會專注在算力比較密集的場景,而不會做終端的應用。IPU也更能夠適應未來整個行業的變化非常快,模型的大小每3.5個月就會增長一倍。並且,模型參數增加一倍,但最後還是要拆成不同的尺寸,算力需求的增長將不止兩倍,所以未來的算力需求將會呈現指數型的增長。
盧濤補充表示,現在AI做的主要是圖片的目標識別,自然語言處理對算力的要求更高,未來視頻的分析需要更高的算力,如何把AI應用到AR、VR都對算力提出了巨大的要求。
需要指出的是,使用相同的IPU就能進行AI訓練和推理。在大家普遍的認知中,推理和訓練對于算力有着巨大的需求,不過Nigel Toon認為,訓練和推理技術上本質上沒有很大區別,先通過數據訓練出模型,部署的時候實際上是通過推理是把模型拿出來。在未來的應用里,部署的場景可能是推理,同時還要不停地訓練和更新這個模型。

“從架構的角度,這對我們非常重要,因為隨着機器學習演進,系統將能夠從經驗中學習。推理性能表現的關鍵包括低延遲、能使用小模型、小批次,以及可能會嘗試導入稀疏性的訓練模型;IPU可以有效地完成所有這些事情。”
據介紹,在一個4U機箱中,16顆IPU共同合作協作進行訓練,每顆IPU可以執行獨立的推論任務,並由一個CPU上執行的虛擬機來控制,最終得到一個可用于訓練的硬件。一旦模型被訓練、布署,隨着模型演進且想要從經驗中學習時,就可以采用相同的硬件。
盧濤進一步指出,由于IPU架構的特性,模型部署的時候精度和訓練的結果會保持一致,另外在 IPU 里面要做的計算跟要處理的處理都是在本地,以及 IPU 這種超大規模小型向量機的架構,使得IPU做稀疏化應用場景的時候,天生性能就會更好。所以IPU既可以用于云服務器,在邊緣端,IPU也非常擅長,自動駕駛就會是我們很重要的應用場景。
但還有一個關鍵問題,擁有如此多核心和片內存儲的IPU是否會成本高昂?Nigel Toon表示不一定,因為客戶都會關注效能,如果 IPU的架構在實際應用場景實現幾倍甚至幾十倍的性能優勢時,實際的總體擁有成本還是大幅降低。
有意思的是,在技術創新的同時,Graphcore也進行了商業模式的創新。Nigel Toon表示,我們目前沒有采用傳統芯片銷售的模式,我們更多的是通過合作,有兩大類公司會是我們的合作伙伴,一類是服務器公司,目前我們已經與戴爾易安信合作推出了IPU服務器,和中國的服務器廠商合作進展也很快,估計很快就會有搭載我們IPU的服務器上市。
另外一類是云服務提供商,在新的時代,IT產品交付給最終的用戶,云服務廠商非常重要。我們會和中國、美國的公司都進行合作,但具體的合作暫時還處于保密階段。
最近,Graphcore宣布與微軟的具體合作內容,並正式發布Microsoft Azure上Graphcore智能處理單元(IPU)的預覽版,這是公有云領導供應商首次提供GrapchoreIPU。目前,Azure上的Graphcore IPU預覽版現已開放供用戶注冊,專注于突破NLP界限並在機器智能方面取得新突破的開發者可獲得優先訪問權限。
對于中國市場,Nigel Toon表示中國是Graphcore非常重要的策略性市場,Graphcore的中國公司不僅會有銷售和市場,還會注重工程技術方面的投入,會有很多定制化的開發工作,更好地與本地的社區、創新者一起用好IPU。




