

北京时间1月25日早间消息,今日凌晨,DeepMind与暴雪进行了联合直播,在直播中公布了谷歌最新AI程序AlphaStar与《星际争霸2》职业选手此前的比赛结果,名为“AlphaStar”的人工智能在与两位人类职业选手“TLO”和“MaNa”的比赛中,均以5比0取胜。
最后直播的一场比赛中,DeepMind限制了AlphaStar的游戏视角,并在没有测试的前提下与MaNa进行比赛,让人类终于赢了一场。最终总成绩定格在10-1。
这次比赛是在去年12月进行的。在与TLO的对决中,因为目前AlphaStar的训练只针对神族,所以它选择的是虫族,而TLO只能选择神族。TLO在5次对决中竭尽全力,可惜还是完败给AlphaStar。
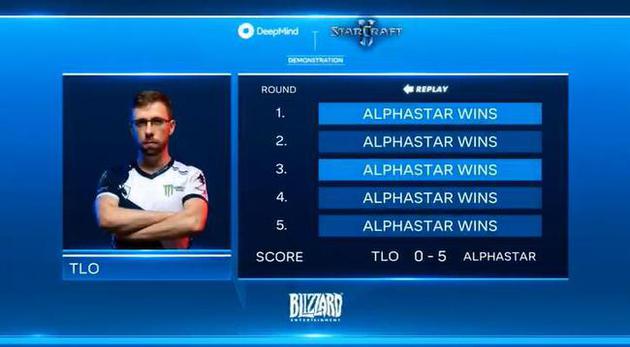
AlphaStar 5-0 TLO
接下来,另一个AlphaStar代理挑战神族玩家MaNa。在一些对决中,双方旗鼓相当,但是AlphaStar还是5战全胜,零封MaNa。
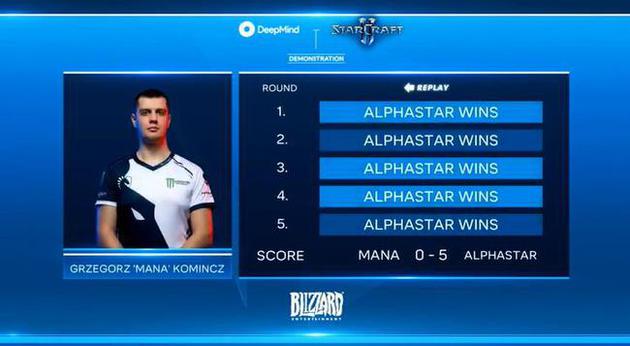
AlphaStar 5-0 MaNa
而在最后直播的一场比赛中,MaNa再次与新的AlphaStar代理对决,这次MaNa终于赢了一场。DeepMind限制了AlphaStar的游戏视角,并在没有测试的前提下与MaNa进行比赛,因此让人类终于赢了一场。最终总成绩定格在10-1。
赛后TLO评价说:“在我们看来,MaNa打得不好,相信我,与AlphaStar这样的对手对决是一件很头痛的事,因为AlphaStar与人类完全不同,你之前没有碰到过这样的对手。AlphaStar给人留下深刻印象,的确是空前强大的游戏AI。”
在对战中,AlphaStar展示了惊人的微操技艺。它可以让受伤单元快速后撤,让满血单元前移。不只如此,AlphaStar还通过前进来控制战斗节奏,只有在适当的时候才后退,避免造成过大伤害。美国科技网站ExtremeTech指出,AI之所以能做到这一点,靠的不是高APM(手速),事实上,与人类相比,AlphStar的APM低很多,只是AI的决策更明智。
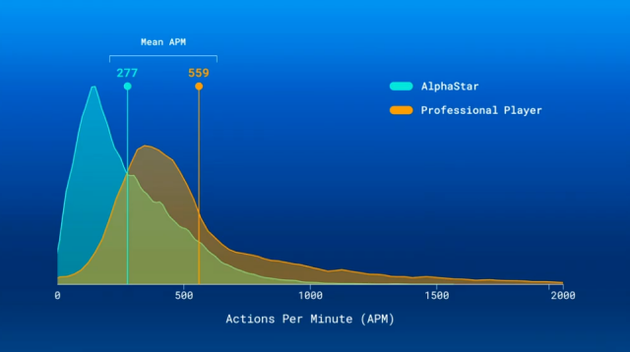
AlphaStar和职业选手APM比较
AI制定的一些战略决策相当有趣。例如,AI经常命令部队在坡道上冲锋,这样做很危险,因为向上冲时视野受限,不过AI的做法似乎很管用。还有,AlphaStar会用一堆建筑封住坡道,这种策略人类也经常使用,非常实用,AI会用这种方法保护自己的基地。
直到最后的直播比赛,人类才找到代理的一个缺陷。当时,AlphaStar代理调集几乎所有部队攻打MaNa的基地,MaNa将几个战斗单元传送到AlphaStar基地的后方,每次传送之后,AlphaStar都会让军队回头营救,这样MaNa就有了足够的时间扩张部队,反击AI。
最终,AlphaStar赢了职业玩家10次,只输了1次。ExtremeTech认为,如果AlphaStar能从最后一局中汲取教训,下一次将会无敌。
AlphaGo的首席作者大卫席尔瓦(Dave Sliver)同时也是AlphaStar团队的核心人物,在直播中分享了AlphaStar技术上的一些细节。不过直播中并未公布AlphaStar后续的正式比赛计划。
AlphaStar是一种卷积神经网络。研发团队用职业玩家的录像训练网络,然后借助对战模式,研究人员训练AlphaStar,教它如何打败人类。随着时间的推移,研究人员挑选出5个最好的“代理”,让它们与世界上了些最棒的《星际争霸2》玩家对决。这样训练出来的AlphaStar积累了相当于200多年的实践经验。
11月份,在Blizzcon大会上,DeepMind就曾表示,机器学习算法在游戏进行到大约一半时,就击败了疯狂难度的游戏内置AI工具。
现代竞技游戏相当复杂,《星际争霸》正是这样一款游戏。玩家需要瞬间做出决策,比如应该关注哪个区域。一般来说,在决策过程中涉及到不完全信息,也就是说你无法完全知道对手正在做什么,也不知道接下来会面对什么。
OpenAI的工程师唐杰(Jie Tang,音译)说:“这类实时战略游戏非常有趣,它是测试现代AI研究的好标准。”为什么这样说呢?有几个原因。首先就是“长期视野”,也就是做出决定、看到结果之间有着很长的时间。如果是国际象棋或者围棋,通过分析棋盘上的变化就能马上判断效果。
但《星际争霸》不太一样。唐杰说:“在一个小时的时间内,每一秒你都要做十个决定,所以有成千上万的举动你要考虑进去。所以你要好好分配,为什么我能赢得游戏?是不是因为我早早制造了矿工?这可是一个很难的问题。”
从《星际争霸1》到《星际争霸2》,20年来有许多人在网上玩游戏,积累了大量数据。如果是象棋或者围棋,数据没有那么丰富。
美国媒体Vox指出,在对决演示中,有些比赛持续的时间长一些,有时短一些,不过没有一盘持续时间超过半小时,所以我们还无法看到AlphaStar在后期对决中的表现,这点也向我们证明,暂时还没有谁能将AlphaStar拖入后期对决。
实际上,AlphaStar不完美的地方还很多。例如,有时AlphaStar会建造一些无用单位,有时还会陷入困惑,在一场比赛中,AI围着一个点来回游荡,漫无目地,评论员看不懂。有些工具本可以使用,便是AI没有用。无论怎样,最终AI还是打败了人类。
与TLO对决之后,DeepMind又将AlphaStar回炉,再次训练。经过14天的实时训练之后,AlphaStar回归,这次用联赛模式对决,它积累了200年的游戏经验,表现更加出色。在战术上,AI没有明显失误。对于人类观察者来说,AI的决定并非总是有意义,但它没有犯下明显错误。这次对手换成MaNa,他也没有犯下明显错误,但是AI合兵散兵的能力仍然技高一筹,最终拿下比赛。
唐杰说:“非常有趣,非常引人注目。有一样东西是我非常期待的,那就是战略对决机制。”一方面,AI要为游戏制定宏观策略,另一方面,AI要通过执行一系列糟糕的策略而获胜,在这两方面,AlphaStar都做得不错。唐杰说:“AlphaStar制定的高级策略与顶级人类玩家非常相似,另外,它的机制也很完美。”
在10次对决中,AI告诉我们它有一个巨大优势,这个优势是人类欠缺的:凡是地图上能看到的地方,AI都能一览无余,而人类必须依赖摄像头。
DeepMind正在训练新AlphaStar,让它也操纵摄像头。虽然最后一场AlphaStar输给了MaNa,不过新AI只训练了7天。最终AlphaStar会回到战场,向人类“复仇”。
早期AlphaStar有许多缺陷,这些缺陷与最初的AlphaGo有些相似。开始时AlphaGo也能赢,但是经常犯下人类可以察觉的错误。随着优化的继续,目前的AlphaZero不会再犯下人类可谓察觉的错误了。
很明显,AlphaStar仍然有很大的改进空间。AlphaStar之所以能战胜人类,主要还是因为它的微操控制更棒。AI经常利用侧面包抄和机动作战打败人类,之所以做到,靠的是单位控制,它一次可以指控5个战斗单元,人类做不到。还有,从游戏看来,AI无法制定出可以在职业世界广泛流行的策略,换言之,在制定最佳策略时,人类仍然胜过机器算法,AI只是寻找最适合自己的策略,将优势发挥出来。虽然AI的APM和响应时间仍然处在人类触及的范围,但是AI的操作精准度更高,所以它在人类面前仍然有优势,人类与AI对决,并不是很公平。
还有一点要说的是,对战5盘之后,MaNa会根据AlphaStar制定新策略,这是AI做不到的。
Vox认为,不论怎样,AI已经向我们证明,它知道如何佯攻,知道如何发动早期攻击,知道如何应对伏击,知道如何利用地形。这些都向我们证明:AI进步神速。
而ExtremeTech指出,人类一直认为,对于我们自己创造的游戏,人类才是真正的主宰,不过计算机一次又一次证明,它才是高手。谷歌DeepMind开发的算法已经在围棋上击败人类,现在又在《星际争霸2》获得成功。


